

引言
數據科學是一個多學科領域,涉及到統計學、機器學習、數據庫、可視化以及具體的領域知識來從大數據中提取價值和洞見。在眾多領域中,新奧彩作為一種特殊的數據集聚地,其數據科學的應用尤為引人注目。本文將探討新奧彩最新的資料,并使用數據科學的方法對其解析說明,旨在提供一個JKP9.593自由版的數據科學解析框架。
新奧彩資料概覽
新奧彩資料通常包含歷史數據、賠率、勝負概率等信息,這些數據對于預測結果、風險管理和決策制定具有重要意義。JKP9.593自由版提供了一個較為開放的數據訪問平臺,用戶可以在此基礎上進行數據分析和模式識別。
數據科學方法論
數據科學方法論可以被劃分為以下幾個核心步驟:理解問題、數據收集、數據清洗、探索性數據分析(EDA)、特征工程、模型選擇與訓練、模型評估與優化以及最終的部署。在新奧彩數據的分析中,這些步驟尤為重要,以確保我們能夠有效地提取有價值的信息。
理解問題
在進行數據科學分析之前,明確分析的目標是至關重要的。這可能涉及到預測特定比賽的結果、分析投注行為、識別潛在的市場趨勢或是優化投注策略。

數據收集
JKP9.593自由版提供了基本的數據接口,用戶需要根據分析目標收集相應的數據。這可能包括歷史比賽結果、賠率變化、球隊表現統計等。數據來源的多樣性和質量將直接影響最終分析的結果。
數據清洗
數據清洗是數據科學中的一個關鍵步驟,涉及去除錯誤、重復或是不完整的數據。對于新奧彩數據來說,這可能意味著去除無效的投注記錄、修正錯誤的賠率信息等。
探索性數據分析(EDA)
探索性數據分析是對數據的初步探索,使用統計圖表、圖形和計算模型等來概括性地描述數據集中的主要結構、特征和關系。對于新奧彩數據,EDA可以幫助我們識別賠率和結果之間的關聯性、比賽的不確定性等關鍵因子。
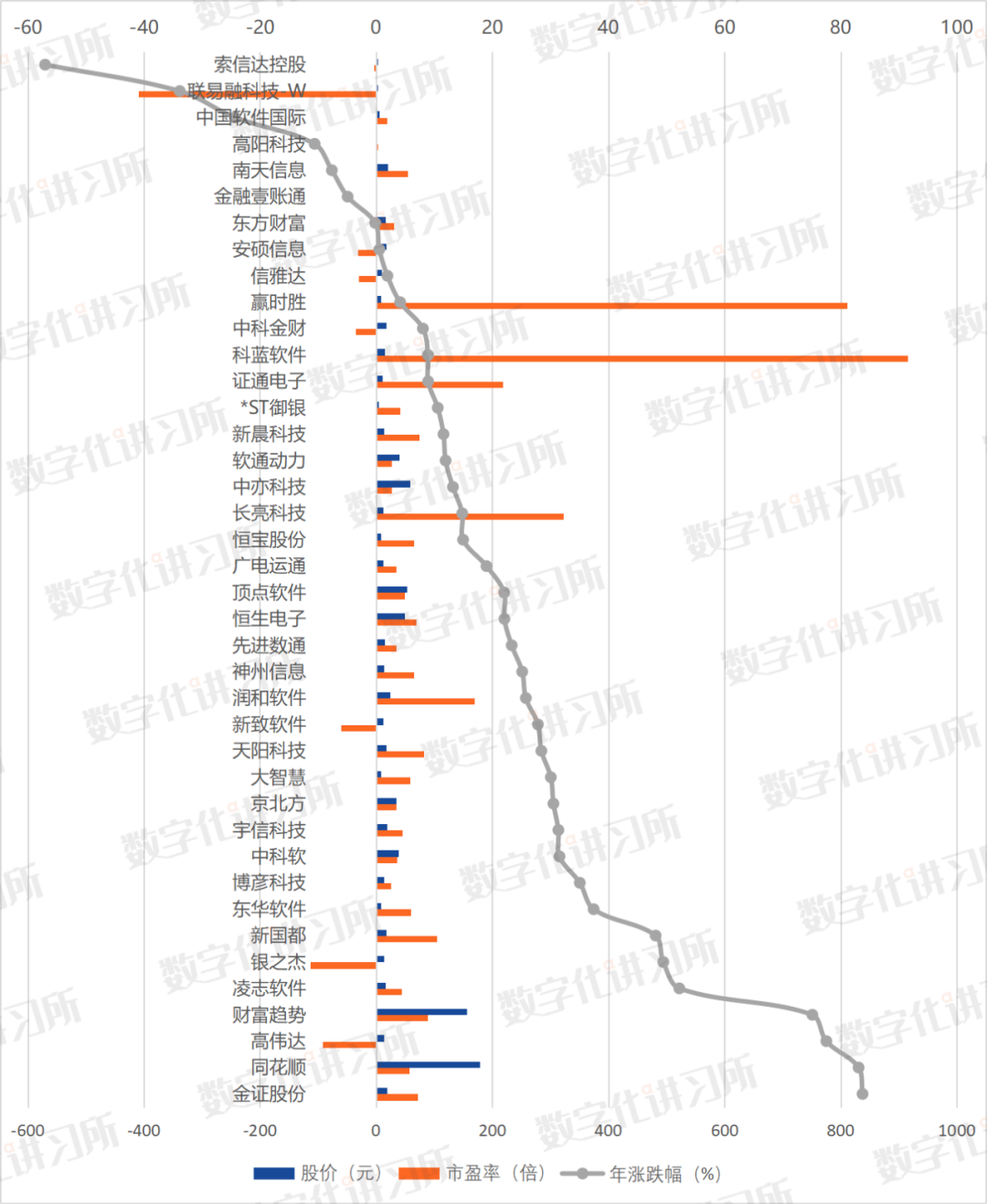
特征工程
特征工程是構造數據特征的過程,這些特征可以直接用于機器學習模型。在新奧彩數據的處理中,特征工程可能涉及到比賽的相關參數、歷史表現統計、賠率變化率等的提取和構造。
模型選擇與訓練
選擇合適的模型來解決特定的問題是數據科學中的關鍵決策。在新奧彩數據的分析中,可能使用的模型包括邏輯回歸、決策樹、隨機森林或神經網絡等。模型的選擇將基于數據的特性和分析目標。
模型評估與優化
模型評估是通過交叉驗證、A/B測試等方法來確定模型的有效性和準確性。優化則是基于評估結果對模型進行調整的過程,可能涉及到調整參數、增加或減少特征等。在新奧彩數據科學中,這一步驟尤為關鍵,因為它直接影響到預測的準確性和可靠性。
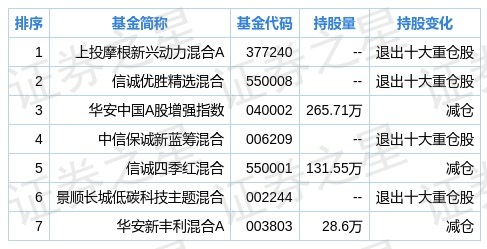
部署與監控
一旦模型經過評估和優化,并證明其有效性,就可以將模型部署到實際應用中。在新奧彩數據的應用中,這可能涉及到實時預測系統、自動化投注決策支持等。監控模型的性能,并根據市場變化不斷調整模型,是保持模型長期有效性的關鍵。
結論
新奧彩領域的數據科學前景廣闊,JKP9.593自由版提供了一個優質的數據科學平臺。通過遵循數據科學的方法論步驟,我們能夠從新奧彩數據中提取有價值的信息,為決策提供科學依據。然而,需要注意的是,這些分析和模型都有一定的局限性,必須結合專業知識和市場情況綜合考慮。




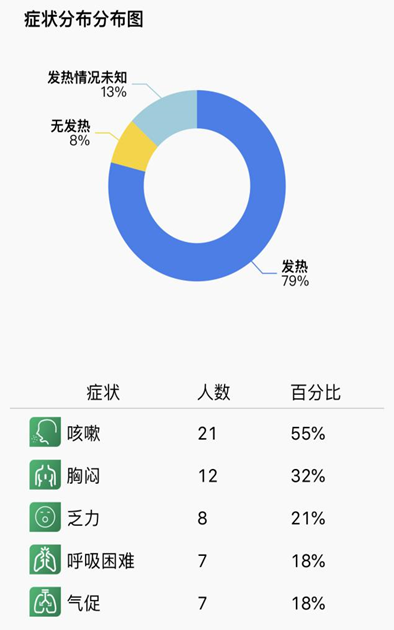



還沒有評論,來說兩句吧...